
Nvidia's controls the AI chips market. By some analysts' estimates, it controls 80% of the AI market. Their products went almost unchallenged for a long time, allowing Nvidia to deepen their moat in the field. They offer the best GPUs in the market, with proprietary APIs exclusive for them in CUDA, tying it all together perfectly with data center-specific hardware enabled by their purchase of Mellanox.
For enterprises big enough, messing up with other exotic solutions will end up costing more. For example, they'll have to figure out data delivery, mess up with code inconsistencies for not using CUDA-enabled cards (which are Nvidia's alone), and usually settle for less optimal hardware.
But the tides are changing. Nvidia won't lose the market any time soon, but their moats aren't as deep as though to be. They are being challenged on all fronts: the better hardware for the task, the CUDA API hegemony, and the integration of all parts.
GPGPUs and the AI field
Deep-learning AI, driven by neural networks (as opposed to machine-learning, often referred to as AI too), is driven by a high volume of high-precision (as in floating-point precision) calculations done in parallel.
By their native architecture, GPUs are better equipped for the task than other computation chips like CPUs. GPGPU - "General-purpose computing on graphics processing units" is the name for any general computing done on GPUs instead of the traditional graphics job intended for them.
To utilize the GPU hardware abilities for parallel, high-precision calculations, programmatic APIs bridge the gap from the developer to the hardware. Multiple APIs exist and have existed for a long time. When AI first gathered steam, Nvidia had CUDA ready while everyone else only had the open-source OpenCL API.
CUDA was far superior to other APIs in any neural network task, specifically through cuDNN that targeted neural networks. So Nvidia had the better hardware as well as a far better way to utilize this hardware.
Framework support
With Nvidia having the better hardware and the only viable API in CUDA, most AI frameworks popping up elected not to bother with other APIs and develop exclusively on the proprietary CUDA API.
Tensorflow had an issue since 2015 regarding OpenCL support which was ignored until last year when it was close with the blogpost of launching OpenCL in mobile TensorFlow. The mobile OpenCL support is due to the fact that mobile GPUs are not Nvidia GPUs, and any way to communicate with them is better than no way. Furthermore, the OpenCL implementation is intended for mobile inference, not server-intensive model training.
On the PyTorch issue from 2017 regarding OpenCL, the maintainers outright say that OpenCL is bad, and other hardware vendors are moving away anyway (AMD with Hip, which we'll talk about).
Nvidia's control
By having the better hardware with the only viable, proprietary API out there at the right time, Nvidia built control on the market that thickened every year.
With models and almost every research paper built on top of Nvidia's GPUs and CUDA API, catering to their quirks specifically (even if unknowingly), Nvidia put themselves in a position where it is very hard to replace them.
But changes happen slowly.
CUDA dominance challenged
Researchers and programmers' time, multiplied by the time they spend testing their creations, is far more expensive than the hardware. So a model designed on top of CUDA is unlikely to move, even if Nvidia will boil the pricing pot under the enterprises.
"Designed on top of CUDA" can be interpreted as written with CUDA directly. Still, more often, it means written in a common framework like TensorFlow or PyTorch and tested on it, which means that either an abstraction layer on the CUDA level or the frameworks level will work. And that's exactly what is going on.
AMD ROCm (HIP)
ROCm - Radeon Open Compute is the project hub for AMD's open GPU APIs. It's home to the HIP project, which is the equivalent of CUDA in AMD's world. But being the underdog, AMD lures vendors and enterprises in by promising an open standard under open source code free to implement forever. And yes, that includes an implementation of Nvidia cards that AMD maintains.
Creating yet another standard, even if it's open, is nice. It might be better equipped than the old OpenCL for AI work, but it's not enough. So AMD created a tool called HIPify that can automatically transform CUDA code to HIP code. Thus automatically support any past and future CUDA-specific code.
This project has been going on for years now. But recently, it seems like it got to a point where it's good enough and easy enough to be production-ready in multiple applications where GPGPU is needed (which is not only AI).
You can install ports of Tensorflow and PyTorch, and many other frameworks that work with HIP. In addition, the Blender project implemented GPU acceleration for its Cycles render engine using HIP in Blender 3.0, marking another milestone in the maturity of this project.
The project isn't perfect yet, and enterprises can't simply switch to AMD cards and expect their TensorFlow model to just work™. But it's coming there, and if an organization is very tight on budget or starting a new project from scratch (so it wouldn't have the conversion pains) - it can work, especially as AMD's hardware becomes better.

Tensorflow on special hardware
I'll get to it in more detail on the next part, but mega-corps with special hardware for AI already offer support directly within the frameworks for their hardware.
TensorFlow has native support for Google TPU, as Google controls both projects. AWS Trainium has the Neuron SDK to support code from TensorFlow and PyTorch.
So theoretically, if you are big enough, aka Google and Amazon (Apple and Facebook have internal, non-outward-facing solutions), you can build the hardware and maintain the special software to break CUDA's monopoly.
Other solutions
I'll mention it here because otherwise I know I'll get angry emails back. There are other APIs too. But, no, none of them is a serious competitor. Not only because of lack of resources but also because of weird enterprise pettiness. Intel OneAPI is such a project. It's obvious they won't shape up to AMD ROCm project, but OFCOURSE they won't join AMD. No, they must have their own API. Sigh.
The hardware challenge
Allow me to start from the end here - Nvidia is so worried about third-party hardware for AI that they are willing to break their monopoly of CUDA and allow third parties to implement it on their hardware. If they are successful at that, they'll lose some of the hardware market but maintain CUDAs power.
Specialized hardware
Neural-networks training calls for high-precision floating-point calculation made in parallel. It's a happy coincidence that GPUs natively had many FP32 computes that play this game, but it's not the best way to play this game.
Other floating-point hardware formats can perform better for neural networks. Such is the BFLOAT16 format, implemented in Google's AI hardware accelerator called TPU. The optimized hardware allows for much higher efficiency and performance than Nvidia currently has.
These specialized optimizations on the hardware level create a new category of AI hardware where, currently, no one has a special advantage. At least not on the hardware level.
It's not a magic bullet, either. Not every model can be optimized for it, and it's not simply a matter of "let's run our code on a TPU instead of GPU". Usually, it'll require a rewrite.
So iterating on previous models will usually call for a stay on the same platform. If it's Nvidia GPU, so be it. But as time goes by, more models are designed for specialized hardware, and more frameworks like TensorFlow allow for better compatibility of the code between the platforms - making the switch easier, if viable.
TPU performance
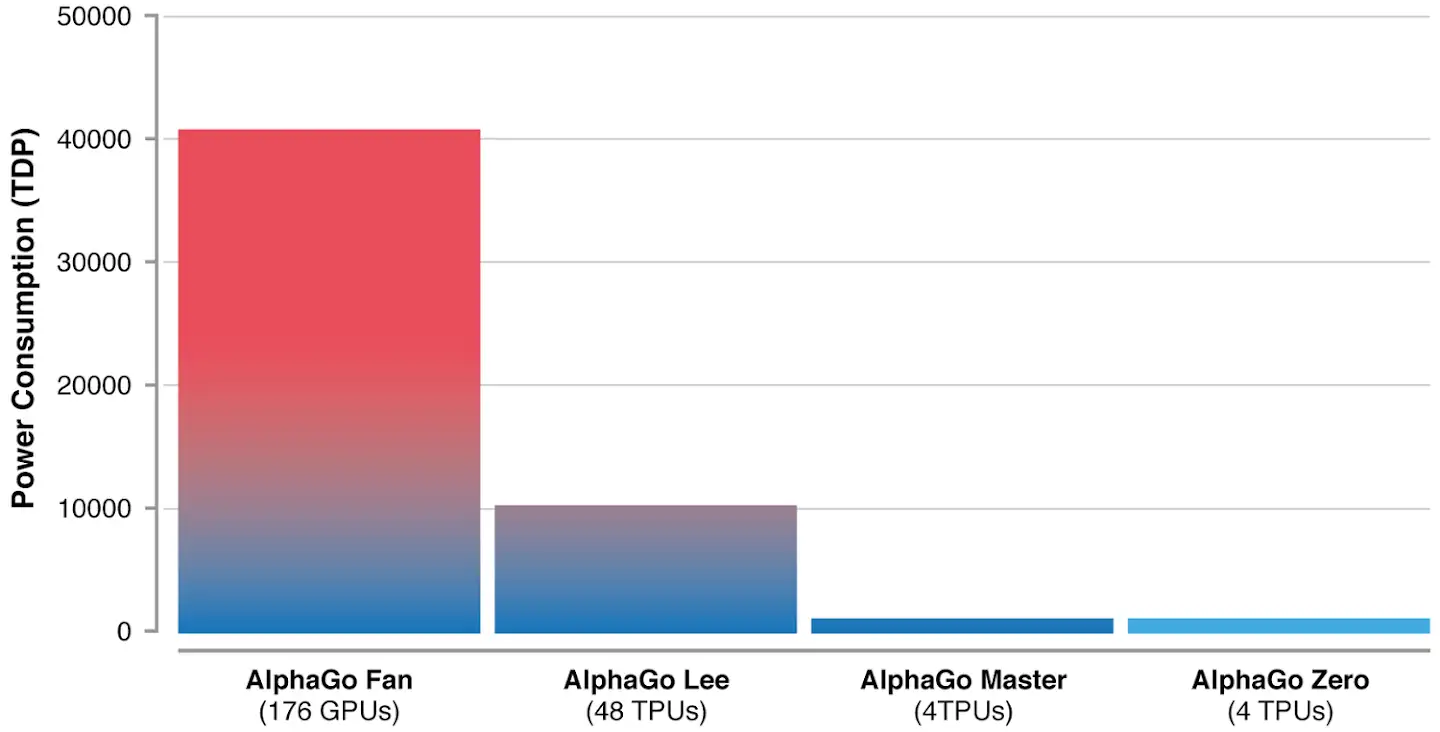
TPUs benchmarks provide an excellent lens to the potential of these specialized hardware cards. Apart from the generic benchmarks that show much better performance, real-world examples like the performance boost to the AlphaGo project after moving to TPUs.
Specialized hardware is crowded
Similar to Google TPUs, there are special AI hardware projects in Amazon, Alibaba, Tencent, Facebook, Apple, and more. Everyone who cares about AI develops proprietary hardware. And some provide them as a service through cloud offerings (Google TPU, Amazon AWS Trainium).
The new hardware is better, cheaper, and breaks the Nvidia CUDA hegemony, hence Nvidia's attempt to have some of these companies implement CUDA. At least if someone will outgrow the cloud offering, they will go back to Nvidia's closed garden. (Prediction: not a chance that will happen).
The future
My conclusion from the research is that hardware for training neural networks will be commoditized in the future, prone to a pricing war. That is not the case at the moment, though. Nvidia can price up their hardware, and almost no one will have a choice.
The ecosystem is also much broader than I described here. For example, in the first paragraph, I mentioned the Mellanox offerings that are part of Nvidia today - if an enterprise runs a large data operation fed into a model retrained continuously - they absolutely need it, and there are no real competitors.
Also, much of the tooling around training models are built on top of Nvidia's hardware and offerings. Even if not intentionally, then by having it tested only on those. No one wants to be the first to use a known tool in an untested environment in a production setting.
So when will it be commoditized? We're years from that point. But I'm focused on long-term investing. I'm not willing to bet on timing the point where Nvidia will have the perfect storm hitting it (in terms of AI, at least). I think Nvidia will not be the "AI leader" of the future. This title will have to go to someone else, probably someone on the software side, not the hardware side.